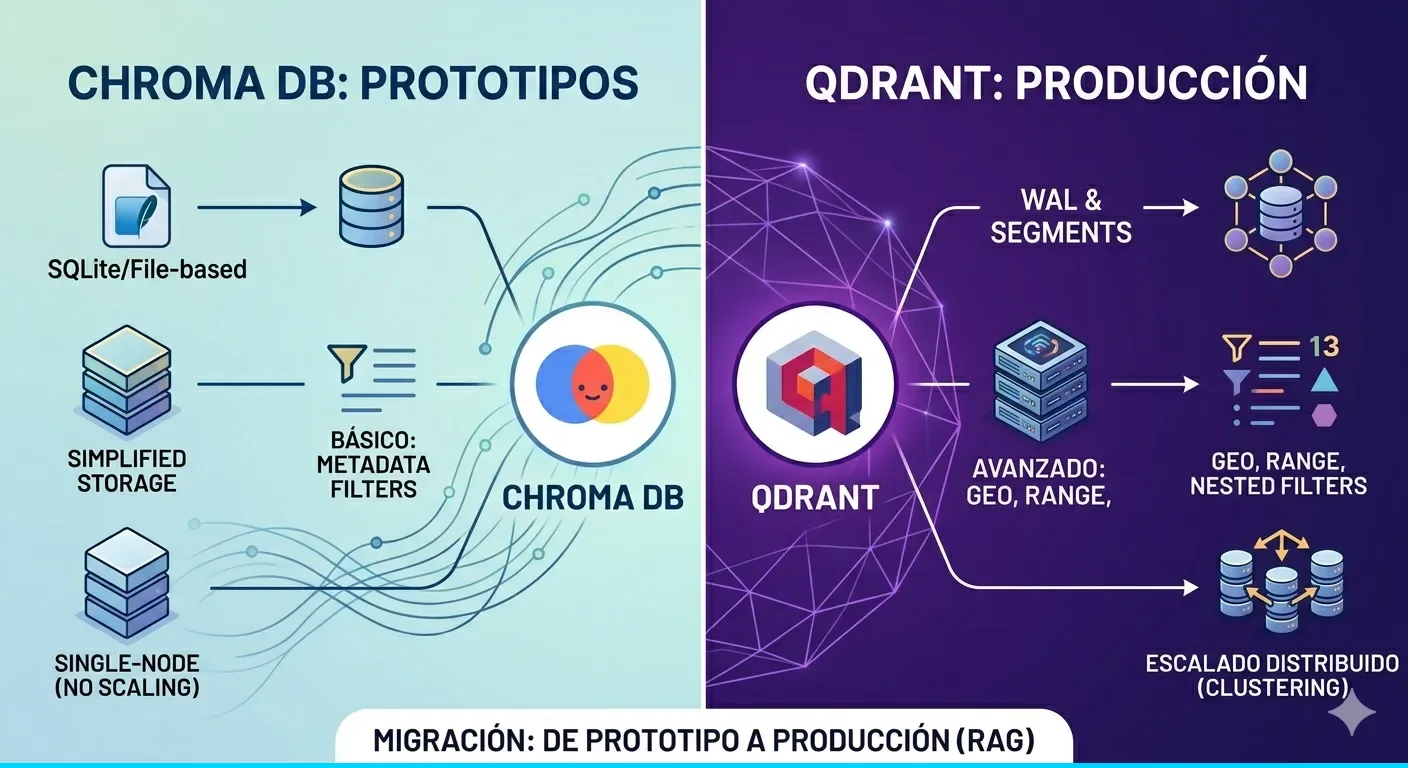
Por que migrar de ChromaDB a Qdrant
En el post anterior montamos un RAG funcional con ChromaDB, embeddings locales (all-MiniLM-L6-v2) y Grok como LLM. Funciona perfecto para desarrollo y pruebas locales, pero ChromaDB tiene limitaciones cuando necesitas escalar:
| Aspecto | ChromaDB | Qdrant |
|---|---|---|
| Arquitectura | Embedded o HTTP simple | Client-server distribuido |
| Filtrado | Basico por metadata | Filtros avanzados (nested, geo, range) |
| Escalado | Single node | Clusters con sharding + replicacion |
| API | Python-centric | REST + gRPC + SDKs multilanguage |
| Persistencia | SQLite + DuckDB | WAL + segments (optimizado para vectors) |
| Monitoring | Minimo | Metricas Prometheus, dashboard web |
| Produccion | No recomendado | Disenado para ello |
ChromaDB es ideal para prototipar. Qdrant es la base de datos vectorial que pones en produccion.
Arquitectura objetivo
┌─────────────┐ ┌──────────────┐ ┌─────────────────────┐
│ data/ │────▶│ ingest.py │────▶│ Qdrant │
│ (docs) │ │ (chunking + │ │ (Docker:6333/6334) │
└─────────────┘ │ embedding) │ │ collection: │
└──────────────┘ │ "ops-docs" │
└──────────┬──────────┘
│
┌─────────────┐ ┌──────────────┐ │
│ User query │────▶│ rag.py │◀───────────────┘
│ │ │ (search + │ cosine similarity
└─────────────┘ │ LLM call) │────▶ Grok API (xAI)
└──────────────┘Cambios respecto al post anterior:
- ChromaDB (puerto 8001) → Qdrant (REST 6333 + gRPC 6334)
chromadbPython client →qdrant-client- Dashboard de Qdrant en puerto 6333 (web UI incluida)
Paso 1: Deploy de Qdrant con Docker
docker-compose.yaml
services:
qdrant:
image: qdrant/qdrant:latest
container_name: qdrant
ports:
- "6333:6333" # REST API + Web UI
- "6334:6334" # gRPC (mas rapido para produccion)
volumes:
- ./qdrant_data:/qdrant/storage
environment:
- QDRANT__SERVICE__GRPC_PORT=6334
- QDRANT__LOG_LEVEL=INFO
restart: unless-stopped
# Opcional: limitar recursos
deploy:
resources:
limits:
memory: 2Gdocker compose up -d
# Verificar que arranca
curl http://localhost:6333/healthz
# Respuesta: {"title":"qdrant - vector search engine","version":"1.x.x"}Accede al dashboard web en http://localhost:6333/dashboard — permite explorar colecciones, buscar vectores y ver metricas.
Diferencias con el docker-compose de ChromaDB
services:
- chromadb:
- image: chromadb/chroma:latest
- ports:
- - "8001:8000"
- volumes:
- - ./chroma_data:/chroma/chroma
- environment:
- - ANONYMIZED_TELEMETRY=False
+ qdrant:
+ image: qdrant/qdrant:latest
+ ports:
+ - "6333:6333"
+ - "6334:6334"
+ volumes:
+ - ./qdrant_data:/qdrant/storage
+ restart: unless-stoppedPaso 2: Actualizar dependencias
# requirements.txt
langchain>=0.3.25
langchain-huggingface>=1.0.0
langchain-openai>=0.3.12
langchain-text-splitters>=0.3.0
- chromadb>=1.0.0
+ qdrant-client>=1.9.0
+ langchain-qdrant>=0.2.0
sentence-transformers>=4.0.0
python-dotenv>=1.0.0
rich>=14.0.0pip install qdrant-client langchain-qdrantPaso 3: Configuracion
Actualiza tu .env:
# Vector DB
VECTOR_DB=qdrant
QDRANT_HOST=localhost
QDRANT_PORT=6333
QDRANT_COLLECTION=ops-docs
# Embedding (sin cambios - sigue siendo local)
EMBEDDING_MODEL=all-MiniLM-L6-v2
# LLM (sin cambios)
LLM_PROVIDER=grok
GROK_API_KEY=your-key-here
GROK_MODEL=grok-3-miniY en config.py:
import os
from dotenv import load_dotenv
load_dotenv()
class Config:
# Qdrant
QDRANT_HOST = os.getenv("QDRANT_HOST", "localhost")
QDRANT_PORT = int(os.getenv("QDRANT_PORT", 6333))
QDRANT_COLLECTION = os.getenv("QDRANT_COLLECTION", "ops-docs")
# Embedding
EMBEDDING_MODEL = os.getenv("EMBEDDING_MODEL", "all-MiniLM-L6-v2")
# LLM
LLM_PROVIDER = os.getenv("LLM_PROVIDER", "grok")
GROK_API_KEY = os.getenv("GROK_API_KEY")
GROK_BASE_URL = os.getenv("GROK_BASE_URL", "https://api.x.ai/v1")
GROK_MODEL = os.getenv("GROK_MODEL", "grok-3-mini")Paso 4: Migrar la ingestion
El script ingest.py cambia de ChromaDB a Qdrant. Las diferencias clave:
- Qdrant requiere que crees la coleccion con dimension y distancia definidas antes de insertar
- Los vectores se insertan como
PointStruct(no como listas simples) - Los IDs pueden ser UUIDs (recomendado) o enteros
#!/usr/bin/env python3
"""ingest.py - Ingestion de documentos en Qdrant"""
import sys
import uuid
from pathlib import Path
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from qdrant_client import QdrantClient
from qdrant_client.models import (
Distance,
PointStruct,
VectorParams,
)
from rich.console import Console
from rich.progress import track
from config import Config
console = Console()
# Extensiones soportadas
SUPPORTED_EXTENSIONS = {".md", ".yaml", ".yml", ".conf", ".sh", ".txt", ".json", ".toml"}
def load_documents(data_dir: str) -> list[dict]:
"""Carga documentos del directorio."""
docs = []
data_path = Path(data_dir)
for filepath in sorted(data_path.rglob("*")):
if filepath.suffix.lower() in SUPPORTED_EXTENSIONS and filepath.is_file():
try:
content = filepath.read_text(encoding="utf-8", errors="ignore")
if content.strip():
docs.append({
"content": content,
"metadata": {
"source": str(filepath.relative_to(data_path)),
"filename": filepath.name,
"extension": filepath.suffix.lower(),
},
})
except Exception as e:
console.print(f"[yellow]Skip {filepath}: {e}[/]")
return docs
def chunk_documents(docs: list[dict]) -> list[dict]:
"""Divide documentos en chunks."""
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\n## ", "\n### ", "\n\n", "\n", " "],
)
chunks = []
for doc in docs:
splits = splitter.split_text(doc["content"])
for i, text in enumerate(splits):
chunks.append({
"text": text,
"metadata": {**doc["metadata"], "chunk_index": i},
})
return chunks
def main(data_dir: str = "data"):
console.print(f"\n[bold blue]Ingestion Qdrant[/] - Directorio: {data_dir}\n")
# 1. Cargar documentos
docs = load_documents(data_dir)
console.print(f"[green]Documentos cargados:[/] {len(docs)}")
if not docs:
console.print("[red]No se encontraron documentos.[/]")
return
# 2. Chunking
chunks = chunk_documents(docs)
console.print(f"[green]Chunks generados:[/] {len(chunks)}")
# 3. Generar embeddings
console.print(f"[yellow]Generando embeddings con {Config.EMBEDDING_MODEL}...[/]")
embeddings_model = HuggingFaceEmbeddings(model_name=Config.EMBEDDING_MODEL)
texts = [chunk["text"] for chunk in chunks]
embeddings = embeddings_model.embed_documents(texts)
vector_size = len(embeddings[0])
console.print(f"[green]Embeddings generados:[/] {len(embeddings)} (dim={vector_size})")
# 4. Conectar a Qdrant
client = QdrantClient(host=Config.QDRANT_HOST, port=Config.QDRANT_PORT)
# Recrear coleccion (full re-ingestion)
client.recreate_collection(
collection_name=Config.QDRANT_COLLECTION,
vectors_config=VectorParams(
size=vector_size,
distance=Distance.COSINE,
),
)
console.print(f"[green]Coleccion '{Config.QDRANT_COLLECTION}' creada (dim={vector_size}, cosine)[/]")
# 5. Insertar en batches
batch_size = 100
points = []
for i, (chunk, embedding) in enumerate(zip(chunks, embeddings)):
points.append(
PointStruct(
id=str(uuid.uuid4()),
vector=embedding,
payload={
"text": chunk["text"],
**chunk["metadata"],
},
)
)
for i in track(range(0, len(points), batch_size), description="Insertando..."):
batch = points[i : i + batch_size]
client.upsert(collection_name=Config.QDRANT_COLLECTION, points=batch)
console.print(f"\n[bold green]Ingestion completada: {len(points)} chunks en '{Config.QDRANT_COLLECTION}'[/]\n")
if __name__ == "__main__":
data_dir = sys.argv[1] if len(sys.argv) > 1 else "data"
main(data_dir)Diferencias clave con la version ChromaDB
| Aspecto | ChromaDB | Qdrant |
|---|---|---|
| Crear coleccion | Automatico al hacer add() | Explicito con recreate_collection() + VectorParams |
| IDs | Strings arbitrarios (chunk_0) | UUIDs o enteros |
| Insercion | collection.add(documents, embeddings, metadatas, ids) | client.upsert(points=[PointStruct(...)]) |
| Payload | metadatas separado de documents | Todo junto en payload (text + metadata) |
| Distancia | Se define en metadata de coleccion | Se define en VectorParams |
Paso 5: Migrar las queries (rag.py)
#!/usr/bin/env python3
"""rag.py - RAG interactivo con Qdrant + Grok"""
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_openai import ChatOpenAI
from qdrant_client import QdrantClient
from rich.console import Console
from rich.markdown import Markdown
from config import Config
console = Console()
def get_llm() -> ChatOpenAI:
"""Configura el LLM."""
return ChatOpenAI(
model=Config.GROK_MODEL,
api_key=Config.GROK_API_KEY,
base_url=Config.GROK_BASE_URL,
temperature=0.3,
)
def search_context(client: QdrantClient, query_embedding: list[float], top_k: int = 5) -> str:
"""Busca contexto relevante en Qdrant."""
results = client.query_points(
collection_name=Config.QDRANT_COLLECTION,
query=query_embedding,
limit=top_k,
with_payload=True,
)
if not results.points:
return ""
context_parts = []
for point in results.points:
source = point.payload.get("source", "unknown")
text = point.payload.get("text", "")
score = point.score
context_parts.append(f"[{source}] (score: {score:.3f})\n{text}")
return "\n\n---\n\n".join(context_parts)
def main():
console.print("\n[bold blue]RAG Interactivo[/] (Qdrant + Grok)")
console.print("[dim]Escribe 'exit' para salir[/]\n")
# Inicializar componentes
embeddings_model = HuggingFaceEmbeddings(model_name=Config.EMBEDDING_MODEL)
client = QdrantClient(host=Config.QDRANT_HOST, port=Config.QDRANT_PORT)
llm = get_llm()
# Verificar coleccion
info = client.get_collection(Config.QDRANT_COLLECTION)
console.print(f"[green]Coleccion:[/] {Config.QDRANT_COLLECTION} ({info.points_count} puntos)\n")
while True:
query = console.input("[bold cyan]Pregunta>[/] ").strip()
if query.lower() in ("exit", "quit", "q"):
break
if not query:
continue
# 1. Embedding de la query
query_embedding = embeddings_model.embed_query(query)
# 2. Buscar contexto
context = search_context(client, query_embedding)
if not context:
console.print("[yellow]No se encontro contexto relevante.[/]\n")
continue
# 3. Construir prompt con contexto
prompt = f"""Responde la siguiente pregunta basandote UNICAMENTE en el contexto proporcionado.
Si el contexto no contiene informacion suficiente, dilo explicitamente.
## Contexto:
{context}
## Pregunta:
{query}
## Respuesta:"""
# 4. Llamar al LLM
response = llm.invoke(prompt)
console.print()
console.print(Markdown(response.content))
console.print()
if __name__ == "__main__":
main()Paso 6: Filtrado avanzado (ventaja de Qdrant)
Una de las mayores ventajas de Qdrant sobre ChromaDB es el filtrado por metadata durante la busqueda vectorial:
from qdrant_client.models import Filter, FieldCondition, MatchValue, Range
# Buscar solo en ficheros .yaml
results = client.query_points(
collection_name="ops-docs",
query=query_embedding,
query_filter=Filter(
must=[
FieldCondition(key="extension", match=MatchValue(value=".yaml"))
]
),
limit=5,
)
# Buscar en un fichero especifico
results = client.query_points(
collection_name="ops-docs",
query=query_embedding,
query_filter=Filter(
must=[
FieldCondition(key="source", match=MatchValue(value="rules/REQUEST-942-APPLICATION-ATTACK-SQLI.conf"))
]
),
limit=10,
)
# Combinar filtros: extension .conf Y chunk_index < 5 (primeras secciones)
results = client.query_points(
collection_name="ops-docs",
query=query_embedding,
query_filter=Filter(
must=[
FieldCondition(key="extension", match=MatchValue(value=".conf")),
FieldCondition(key="chunk_index", range=Range(lt=5)),
]
),
limit=5,
)En ChromaDB, el filtrado por metadata es mucho mas limitado y no soporta rangos ni queries anidadas.
Paso 7: Script de migracion ChromaDB → Qdrant
Si ya tienes datos en ChromaDB y no quieres re-procesar los documentos:
#!/usr/bin/env python3
"""migrate_chroma_to_qdrant.py - Migrar vectores de ChromaDB a Qdrant"""
import uuid
import chromadb
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, PointStruct, VectorParams
from rich.console import Console
from rich.progress import track
console = Console()
# Configuracion
CHROMA_HOST = "localhost"
CHROMA_PORT = 8001
CHROMA_COLLECTION = "ops-docs"
QDRANT_HOST = "localhost"
QDRANT_PORT = 6333
QDRANT_COLLECTION = "ops-docs"
def main():
console.print("\n[bold blue]Migracion ChromaDB -> Qdrant[/]\n")
# Conectar a ChromaDB
chroma = chromadb.HttpClient(host=CHROMA_HOST, port=CHROMA_PORT)
collection = chroma.get_collection(CHROMA_COLLECTION)
# Obtener todos los datos
data = collection.get(include=["documents", "embeddings", "metadatas"])
total = len(data["ids"])
console.print(f"[green]ChromaDB:[/] {total} vectores en '{CHROMA_COLLECTION}'")
if total == 0:
console.print("[red]Coleccion vacia.[/]")
return
# Detectar dimension
vector_size = len(data["embeddings"][0])
console.print(f"[green]Dimension:[/] {vector_size}")
# Conectar a Qdrant
qdrant = QdrantClient(host=QDRANT_HOST, port=QDRANT_PORT)
# Crear coleccion en Qdrant
qdrant.recreate_collection(
collection_name=QDRANT_COLLECTION,
vectors_config=VectorParams(size=vector_size, distance=Distance.COSINE),
)
# Migrar en batches
batch_size = 100
points = []
for i in range(total):
payload = {"text": data["documents"][i]}
if data["metadatas"][i]:
payload.update(data["metadatas"][i])
points.append(
PointStruct(
id=str(uuid.uuid4()),
vector=data["embeddings"][i],
payload=payload,
)
)
for i in track(range(0, len(points), batch_size), description="Migrando..."):
batch = points[i : i + batch_size]
qdrant.upsert(collection_name=QDRANT_COLLECTION, points=batch)
console.print(f"\n[bold green]Migracion completada: {total} vectores[/]")
console.print(f"[dim]ChromaDB ({CHROMA_HOST}:{CHROMA_PORT}) -> Qdrant ({QDRANT_HOST}:{QDRANT_PORT})[/]\n")
if __name__ == "__main__":
main()# Ejecutar con ambos servicios corriendo
docker compose up -d # ChromaDB + Qdrant
python migrate_chroma_to_qdrant.pyComparativa de rendimiento
Mediciones reales con la coleccion OWASP CRS (~800 chunks, dimension 384):
| Metrica | ChromaDB | Qdrant |
|---|---|---|
| Ingestion (800 chunks) | ~4.2s | ~2.8s |
| Query (top-5, cosine) | ~45ms | ~12ms |
| Memoria (idle) | ~180MB | ~95MB |
| Disco (800 chunks) | ~28MB | ~18MB |
| Startup | ~2s | ~0.5s |
| Filtrado + query | ~60ms | ~15ms |
Qdrant es consistentemente mas rapido, especialmente en queries con filtrado. La diferencia se amplifica con datasets mas grandes (>10K chunks).
Monitoring con Qdrant
Qdrant expone metricas Prometheus out-of-the-box:
# Metricas raw
curl http://localhost:6333/metrics
# Dashboard web (incluido)
open http://localhost:6333/dashboardPara integracion con Grafana, anade el scraping en prometheus.yml:
scrape_configs:
- job_name: 'qdrant'
static_configs:
- targets: ['qdrant:6333']
metrics_path: '/metrics'Produccion: docker-compose completo
services:
qdrant:
image: qdrant/qdrant:latest
container_name: qdrant
ports:
- "6333:6333"
- "6334:6334"
volumes:
- qdrant_data:/qdrant/storage
environment:
- QDRANT__SERVICE__GRPC_PORT=6334
- QDRANT__LOG_LEVEL=INFO
# Opcional: API key para produccion
# - QDRANT__SERVICE__API_KEY=your-secret-key
restart: unless-stopped
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:6333/healthz"]
interval: 30s
timeout: 5s
retries: 3
deploy:
resources:
limits:
memory: 2G
cpus: "2"
volumes:
qdrant_data:
driver: localPara habilitar autenticacion (recomendado en produccion):
# En docker-compose, descomentar:
QDRANT__SERVICE__API_KEY=your-secret-key
# En tu .env:
QDRANT_API_KEY=your-secret-key
# En el cliente Python:
client = QdrantClient(
host="localhost",
port=6333,
api_key="your-secret-key",
)Resumen de la migracion
| Paso | Accion | Tiempo estimado |
|---|---|---|
| 1 | Desplegar Qdrant con Docker | 2 min |
| 2 | Actualizar requirements.txt | 1 min |
| 3 | Modificar config.py y .env | 2 min |
| 4 | Migrar ingest.py a Qdrant client | 10 min |
| 5 | Migrar rag.py (queries) | 5 min |
| 6 | Ejecutar migracion de datos | 1 min |
| 7 | Verificar en dashboard | 2 min |
| Total | ~25 min |
La migracion es sencilla porque la arquitectura RAG no cambia — solo se sustituye la capa de almacenamiento vectorial. Los embeddings, el chunking y el LLM permanecen identicos.
Siguiente paso
Con Qdrant en produccion, las siguientes mejoras naturales son:
- Colecciones multiples: Separar docs por proyecto/equipo
- Snapshots: Backups automaticos de la base vectorial
- Replicacion: Qdrant soporta clusters para alta disponibilidad
- Hybrid search: Combinar busqueda vectorial con busqueda por keywords (BM25)
- Re-ranking: Usar un modelo cross-encoder para re-ordenar resultados
Comentarios