
Introduccion
En el post anterior construimos un RAG local con ChromaDB, LangChain y Grok. Era funcional pero minimalista: CLI basico, ingesta manual, sin evaluacion de calidad y sin memoria entre preguntas.
En este post implementamos 5 mejoras que lo convierten en un sistema mas profesional y usable en el dia a dia.
1. Interfaz web con Streamlit
La CLI esta bien para pruebas rapidas, pero una interfaz web facilita el uso diario y permite visualizar fuentes y historial.
app.py
import streamlit as st
from rag import search_context, get_llm, ConversationHistory
from config import Config
st.set_page_config(page_title="RAG Ops", page_icon="🔍", layout="wide")
st.title("RAG Ops - Asistente de Infraestructura")
# Sidebar: configuracion
provider = st.sidebar.selectbox("Proveedor LLM", ["grok", "nvidia"])
collection = st.sidebar.selectbox("Coleccion", get_collections())
# Historial en session_state
if "messages" not in st.session_state:
st.session_state.messages = []
# Chat interface
for msg in st.session_state.messages:
with st.chat_message(msg["role"]):
st.markdown(msg["content"])
if prompt := st.chat_input("Pregunta sobre tu infraestructura..."):
st.session_state.messages.append({"role": "user", "content": prompt})
# Buscar contexto y generar respuesta
context = search_context(prompt, collection)
response = generate_response(prompt, context, provider)
st.session_state.messages.append({"role": "assistant", "content": response})Ejecutar con:
# Desde el virtualenv del proyecto
source .venv/bin/activate
streamlit run app.py --server.port 8501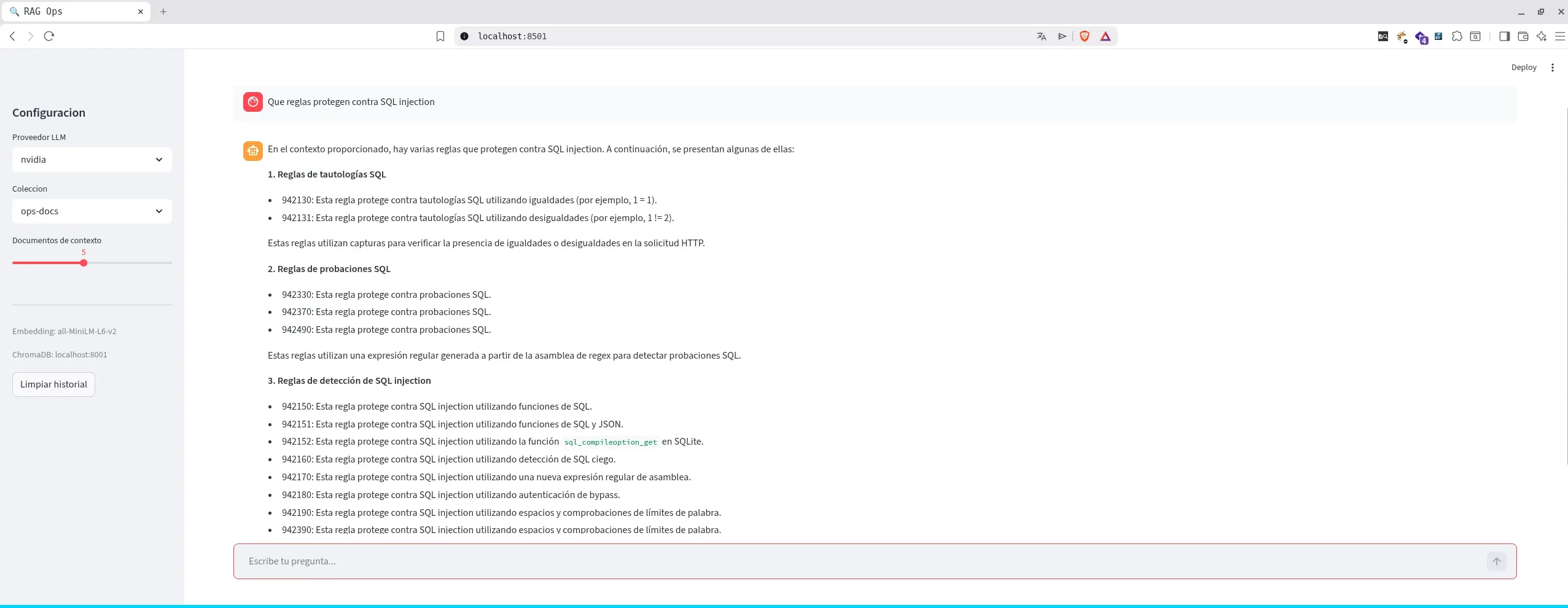
2. Ingesta automatica con Watcher
En vez de ejecutar python ingest.py cada vez que anadimos documentos, un watcher monitoriza el directorio y re-ingesta automaticamente.
watcher.py
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
from ingest import ingest
from config import Config
class DocsHandler(FileSystemEventHandler):
def on_created(self, event):
if event.src_path.endswith(('.md', '.txt', '.pdf')):
print(f"Nuevo fichero detectado: {event.src_path}")
ingest(Config.WATCH_DIR, Config.CHROMA_COLLECTION)
def on_modified(self, event):
if event.src_path.endswith(('.md', '.txt', '.pdf')):
print(f"Fichero modificado: {event.src_path}")
ingest(Config.WATCH_DIR, Config.CHROMA_COLLECTION)
def watch():
observer = Observer()
observer.schedule(DocsHandler(), Config.WATCH_DIR, recursive=True)
observer.start()
print(f"Monitorizando {Config.WATCH_DIR}...")
observer.join()Ejecutar como servicio o en background:
source .venv/bin/activate
python watcher.py &Cada vez que se anade o modifica un fichero .md, .txt o .pdf en el directorio de datos, la ingesta se dispara automaticamente.
3. Evaluacion de calidad con RAGAS
Sin metricas no sabes si tu RAG funciona bien. RAGAS evalua la calidad de las respuestas contra un test set.
evaluate.py
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_precision
from datasets import Dataset
def run_evaluation(test_set_path: str, collection: str, provider: str):
# Cargar test set (JSON con question + ground_truth)
test_data = load_test_set(test_set_path)
# Para cada pregunta: buscar contexto y generar respuesta
results = []
for item in test_data:
context = search_context(item["question"], collection)
answer = generate_answer(item["question"], context, provider)
results.append({
"question": item["question"],
"answer": answer,
"contexts": [context],
"ground_truth": item["ground_truth"],
})
# Evaluar con RAGAS
dataset = Dataset.from_list(results)
scores = evaluate(dataset, metrics=[faithfulness, answer_relevancy, context_precision])
return scoresTest set (test_set.json)
[
{
"question": "Como configurar una regla de ModSecurity para bloquear SQL injection?",
"ground_truth": "ModSecurity usa reglas SecRule con operadores como @rx..."
}
]Ejecutar:
source .venv/bin/activate
python evaluate.py --test-set test_set.json --collection ops-docsLas metricas clave son:
- Faithfulness: la respuesta se basa en el contexto recuperado (no alucina)
- Answer Relevancy: la respuesta es relevante a la pregunta
- Context Precision: los chunks recuperados son relevantes
4. Multi-coleccion
Un solo bucket para todos los documentos mezcla contextos. Con multi-coleccion separamos por dominio:
# Ingestar documentos de ModSecurity en su coleccion
python ingest.py data/modsecurity modsecurity-docs
# Ingestar runbooks de Kubernetes
python ingest.py data/k8s k8s-runbooks
# Ingestar documentacion de redes
python ingest.py data/networking network-docs
# O todo de golpe con multi-ingesta (cada subdirectorio = coleccion)
python ingest.py --multiEn config.py:
COLLECTIONS = {
"ops-docs": "Documentacion general de operaciones",
"modsecurity-docs": "Reglas y configuracion ModSecurity/CRS",
"k8s-runbooks": "Runbooks de Kubernetes",
}Desde la interfaz web o CLI puedes seleccionar la coleccion:
python rag.py -c modsecurity-docs -q "Como excluir la regla 942100?"5. Memoria conversacional
Sin memoria, cada pregunta es independiente. Con historial el asistente mantiene contexto:
> Que es el paranoia level en CRS?
El paranoia level controla la agresividad de las reglas...
> Y como lo cambio a nivel 2?
Para cambiar a PL2, edita crs-setup.conf y establece tx.paranoia_level=2...La implementacion usa una clase ConversationHistory que mantiene los ultimos N turnos y los inyecta en el prompt:
class ConversationHistory:
def __init__(self, max_turns: int = 5):
self.messages = []
self.max_turns = max_turns
def add(self, role: str, content: str):
self.messages.append({"role": role, "content": content})
max_messages = self.max_turns * 2
if len(self.messages) > max_messages:
self.messages = self.messages[-max_messages:]
def get_formatted(self) -> str:
if not self.messages:
return ""
parts = ["HISTORIAL DE CONVERSACION:"]
for msg in self.messages:
role = "Usuario" if msg["role"] == "user" else "Asistente"
parts.append(f"{role}: {msg['content'][:300]}")
return "\n".join(parts)En Streamlit se persiste via st.session_state, en CLI se mantiene durante la sesion interactiva.
Arquitectura actualizada
rag-ops/
├── app.py # Interfaz web Streamlit
├── rag.py # Pipeline RAG con memoria
├── ingest.py # Ingesta multi-coleccion
├── watcher.py # Auto-ingesta con watchdog
├── evaluate.py # Evaluacion RAGAS
├── config.py # Configuracion centralizada
├── test_set.json # Test set para evaluacion
├── docker-compose.yaml # ChromaDB
├── data/ # Documentos por dominio
│ ├── modsecurity/
│ ├── k8s/
│ └── networking/
└── requirements.txtSetup del proyecto
1. Clonar y crear entorno virtual
git clone <repo> rag-ops && cd rag-ops
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt2. Levantar ChromaDB
docker compose up -d3. Configurar variables de entorno
Crea un fichero .env en la raiz con tus API keys:
LLM_PROVIDER=grok
GROK_API_KEY=tu-api-key-aqui
CHROMA_HOST=localhost
CHROMA_PORT=80014. Ingestar documentos
source .venv/bin/activate
# Ingesta simple (todo en una coleccion)
python ingest.py data ops-docs
# Ingesta multi-coleccion (cada subdirectorio = coleccion)
python ingest.py --multi5. Ejecutar
source .venv/bin/activate
# CLI interactivo
python rag.py
# Interfaz web
streamlit run app.py --server.port 8501
# Watcher en background
python watcher.py &Dependencias (requirements.txt)
langchain>=0.3.25
langchain-huggingface>=1.0.0
langchain-openai>=0.3.12
langchain-text-splitters>=0.3.0
chromadb>=1.0.0
sentence-transformers>=4.0.0
python-dotenv>=1.0.0
rich>=14.0.0
streamlit>=1.38.0
watchdog>=4.0.0
ragas>=0.2.0
datasets>=3.0.0Conclusiones
Con estas 5 mejoras pasamos de un prototipo CLI a un sistema RAG mas completo:
| Mejora | Beneficio |
|---|---|
| Streamlit | Uso diario sin terminal |
| Watcher | Documentos siempre actualizados |
| RAGAS | Metricas objetivas de calidad |
| Multi-coleccion | Contexto separado por dominio |
| Memoria | Conversaciones naturales con seguimiento |
El siguiente paso natural seria migrar de ChromaDB a Qdrant para un entorno mas robusto en produccion, aplicando estas mismas mejoras sobre el nuevo backend vectorial.
Comentarios